
ZooKeeper 内部结构
介绍
本文档包含有关 ZooKeeper 内部工作的信息。它讨论了以下主题:
原子广播
ZooKeeper 的核心是一个原子消息系统,它使所有服务器保持同步。
保证、属性和定义
ZooKeeper 使用的消息传递系统提供的具体保证如下:
-
可靠传递:如果消息
m由一台服务器传递,则消息m最终将由所有服务器传递。 -
总顺序:如果消息一个服务器
a之前传递将在所有服务器之前传递。bab -
因果顺序:如果消息
b是在消息的发送者发送之后a发送的b,则消息a必须在之前排序b。如果发件人先发c后发b,c必须先下b。
ZooKeeper 消息传递系统还需要高效、可靠且易于实施和维护。我们大量使用消息传递,因此我们需要系统能够每秒处理数千个请求。尽管我们可以要求至少 k+1 个正确的服务器来发送新消息,但我们必须能够从相关故障中恢复,例如断电。当我们实施该系统时,我们的时间和工程资源很少,因此我们需要一个工程师可以访问且易于实施的协议。我们发现我们的协议满足了所有这些目标。
我们的协议假设我们可以在服务器之间构建点对点的 FIFO 通道。虽然类似的服务通常假设消息传递可能会丢失或重新排序消息,但鉴于我们使用 TCP 进行通信,我们对 FIFO 通道的假设非常实用。具体来说,我们依赖于 TCP 的以下属性:
-
有序传递:数据按照发送的顺序
m只有在之前发送的所有消息m都已传递后才会传递消息。(由此得出的结论是,如果消息m丢失,所有消息m都将丢失。) -
关闭后无消息:一旦 FIFO 通道关闭,将不会收到任何消息。
FLP 证明,如果可能发生故障,异步分布式系统就无法达成共识。为了确保我们在出现故障时达成共识,我们使用超时。然而,我们依靠时间来获得活力,而不是依靠正确性。因此,如果超时停止工作(例如,时钟倾斜),消息传递系统可能会挂起,但不会违反其保证。
在描述 ZooKeeper 消息传递协议时,我们将讨论数据包、提议和消息:
-
数据包:通过 FIFO 通道发送的字节序列。
-
建议:一个单位的协议。通过与法定数量的 ZooKeeper 服务器交换数据包来商定提案。大多数提案都包含消息,但是 NEW_LEADER 提案是不包含消息的提案示例。
-
Message:要以原子方式广播到所有 ZooKeeper 服务器的字节序列。将消息放入提案并在交付之前达成一致。
如上所述,ZooKeeper 保证消息的总顺序,它也保证提案的总顺序。ZooKeeper 使用 ZooKeeper 事务 id ( zxid ) 公开总排序。所有提案在提出时都将加盖 zxid,并准确反映总排序。提案被发送到所有 ZooKeeper 服务器并在它们的法定人数确认提案时提交。如果提案包含消息,则在提交提案时将传递该消息。确认意味着服务器已将提案记录到持久存储中。我们的仲裁要求任何一对仲裁必须至少有一个公共服务器。我们通过要求所有 quorum 的大小 ( n/2+1) 其中 n 是组成 ZooKeeper 服务的服务器数量。
zxid 有两部分:纪元和计数器。在我们的实现中,zxid 是一个 64 位的数字。我们将高阶 32 位用于纪元,将低阶 32 位用于计数器。因为 zxid 由两部分组成,所以 zxid 既可以表示为数字,也可以表示为一对整数 ( epoch, count )。纪元数代表领导层的变化。每次新领导人上台时,都会有自己的纪元数。我们有一个简单的算法来为提案分配一个唯一的 zxid:领导者简单地增加 zxid 以获得每个提案的唯一 zxid。领导激活将确保只有一个领导使用给定的时期,因此我们的简单算法保证每个提案都有一个唯一的 id。
ZooKeeper 消息传递包括两个阶段:
-
领导者激活:在此阶段,领导者建立系统的正确状态并准备开始提出建议。
-
主动消息传递:在此阶段,领导者接受消息以提议并协调消息传递。
ZooKeeper 是一个整体协议。我们不关注单个提案,而是将提案流视为一个整体。我们严格的排序使我们能够有效地做到这一点,并大大简化了我们的协议。领导力激活体现了这一整体概念。只有当一定数量的追随者(领导者也算作追随者。你总是可以为自己投票)与领导者同步时,领导者才会变得活跃,他们具有相同的状态。此状态由领导者认为已提交的所有提案和跟随领导者的提案(NEW_LEADER 提案)组成。(希望你自己想一想,leader 认为已经提交的提案集是否包括所有真正已经提交的提案?答案是肯定的. 下面,我们说明原因。)
领导者激活
领导者激活包括领导者选举(FastLeaderElection)。只要满足以下条件,ZooKeeper 消息传递并不关心选举领导者的确切方法:
- 领导者看到了所有追随者中最高的zxid。
- 一定数量的服务器已承诺跟随领导者。
在这两个要求中,只有第一个,followers 中最高的 zxid 需要保持才能正确操作。第二个要求,一个法定人数的追随者,只需要以高概率举行。我们将重新检查第二个要求,因此如果在领导者选举期间或之后发生故障并且失去法定人数,我们将通过放弃领导者激活并运行另一次选举来恢复。
领导者选举后,单个服务器将被指定为领导者并开始等待追随者连接。其余的服务器将尝试连接到领导者。领导者将通过发送他们丢失的任何提案与追随者同步,或者如果追随者遗漏了太多提案,它将向追随者发送状态的完整快照。
有一个极端情况,在这种情况下,一个有提议的追随者U到达,但领导者看不到。提案是按顺序查看的,因此提案的Uzxids 将高于领导者看到的 zxids。追随者必须在领导人选举之后到达,否则追随者会被选为领导人,因为它已经看到了更高的 zxid。由于提交的提案必须被法定人数的服务器看到,而选举领导者的法定人数的服务器没有看到U,因此没有提交的提议U,因此可以丢弃。当 follower 连接到 leader 时,leader 会告诉 follower 丢弃U。
在领导者与跟随者同步后,新领导者通过获取它所见过的最高 zxid 的纪元 e 并将下一个要使用的 zxid 设置为 (e+1, 0) 来建立一个 zxid 以开始用于新提案,它将提出一个 NEW_LEADER 提案。一旦 NEW_LEADER 提案被提交,领导者将激活并开始接收和发布提案。
这听起来很复杂,但这里是领导者激活期间的基本操作规则:
- 追随者将在与领导者同步后确认 NEW_LEADER 提案。
- 追随者只会从单个服务器确认具有给定 zxid 的 NEW_LEADER 提案。
- 当法定人数的追随者确认后,新领导者将提交 NEW_LEADER 提案。
- 当 NEW_LEADER 提议为 COMMIT 时,跟随者将提交从领导者那里收到的任何状态。
- 在提交 NEW_LEADER 提案之前,新领导者不会接受新提案。
如果领导者选举错误地终止,我们没有问题,因为领导者没有法定人数,因此不会提交 NEW_LEADER 提案。发生这种情况时,领导者和任何剩余的追随者将超时并返回领导者选举。
主动消息
领导者激活完成所有繁重的工作。一旦领导人加冕,他就可以开始提出建议。只要他仍然是领导者,就不会出现其他领导者,因为没有其他领导者能够获得法定人数的追随者。如果确实出现了新的领导者,则意味着该领导者已失去法定人数,新领导者将清理在其领导层激活期间留下的任何混乱。
ZooKeeper 消息传递的操作类似于经典的两阶段提交。
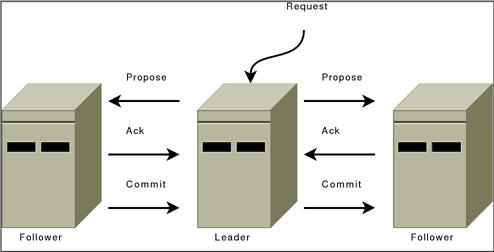
所有的通信通道都是先进先出的,所以一切都按顺序进行。具体而言,观察到以下操作限制:
- 领导者使用相同的顺序向所有追随者发送提案。此外,此顺序遵循已接收请求的顺序。因为我们使用 FIFO 通道,这意味着追随者也可以按顺序接收提案。
- 追随者按照收到的顺序处理消息。这意味着由于 FIFO 通道,消息将按顺序 ACK,领导者将按顺序从跟随者接收 ACK。这也意味着如果消息
m已写入非易失性存储,则之前提出的所有消息m都已写入非易失性存储。 - 一旦达到法定人数的追随者确认了一条消息,领导者就会向所有追随者发出 COMMIT。由于消息是按顺序确认的,因此领导者将按照追随者按顺序接收的 COMMIT 发送。
- 提交按顺序处理。提交提案时,追随者会发送提案消息。
概括
所以你去。为什么它有效?具体来说,为什么新领导者相信的一组提案总是包含任何实际已提交的提案?首先,所有提议都有一个唯一的 zxid,因此与其他协议不同,我们不必担心为同一个 zxid 提议两个不同的值;追随者(领导者也是追随者)按顺序查看和记录提案;提案按顺序提交;一次只有一个活跃的领导者,因为追随者一次只跟随一个领导者;一个新的领导者已经看到了前一个 epoch 中所有已提交的提案,因为它已经看到了来自仲裁服务器的最高 zxid;新领导者看到的任何来自上一个时期的未提交提案都将由该领导者在其激活之前提交。
比较
这不就是 Multi-Paxos 吗?不,Multi-Paxos 需要某种方式来确保只有一个协调器。我们不指望这样的保证。相反,我们使用领导者激活来从领导层变化或旧领导者认为他们仍然活跃中恢复。
这不只是 Paxos 吗?您的活动消息传递阶段看起来就像 Paxos 的第二阶段?实际上,对我们来说,主动消息传递看起来就像不需要处理中止的 2 阶段提交。主动消息传递不同于两者,因为它具有跨提案排序要求。如果我们不保持所有数据包的严格 FIFO 排序,一切都会崩溃。此外,我们的领导者激活阶段与两者都不同。特别是,我们使用 epochs 允许我们跳过未提交的提案块,并且不用担心给定 zxid 的重复提案。
一致性保证
ZooKeeper的一致性保证介于顺序一致性和线性化之间。在本节中,我们将解释 ZooKeeper 提供的确切一致性保证。
ZooKeeper 中的写操作是可线性化的。换句话说,每一个write都会在客户端发出请求和接收到相应响应之间的某个时间点自动生效。这意味着 ZooKeeper 中所有客户端执行的写入可以完全排序,以尊重这些写入的实时顺序。然而,仅仅说写操作是可线性化的是没有意义的,除非我们也讨论读操作。
ZooKeeper 中的读取操作不是线性化的,因为它们可能返回潜在的陈旧数据。这是因为readZooKeeper 中的 a 不是仲裁操作,服务器将立即响应正在执行read. ZooKeeper 这样做是因为它优先考虑读取用例的性能而不是一致性。但是,ZooKeeper 中的读取是顺序一致的,因为read操作会以某种顺序生效,从而进一步尊重每个客户端操作的顺序。解决此问题的常见模式是在发布sync之前发布 a read。这也不能严格保证最新数据,sync因为当前不是仲裁操作。为了说明,考虑两个服务器同时认为自己是领导者的场景,如果 TCP 连接超时小于syncLimit * tickTime. 请注意,这在实践中不太可能发生,但在讨论严格的理论保证时仍应牢记。在这种情况下,可能sync由“领导者”提供陈旧数据,从而允许以下内容read也陈旧。如果在 a 之前执行实际的 quorum 操作(例如 a write) ,则提供了更强的线性化保证read。
总的来说,ZooKeeper 的一致性保证是由有序的顺序一致性的概念正式捕获的,或者OSC(U)准确地说,它介于顺序一致性和线性化之间。
法定人数
原子广播和领导人选举使用法定人数的概念来保证系统的一致视图。默认情况下,ZooKeeper 使用多数仲裁,这意味着在这些协议之一中发生的每次投票都需要多数投票。一个例子是确认领导者提议:领导者只有在收到来自法定人数的服务器的确认后才能提交。
如果我们从对多数的使用中提取我们真正需要的属性,我们只需要保证用于通过投票(例如,确认领导者提议)来验证操作的进程组在至少一个服务器中成对相交。使用多数可以保证这样的属性。但是,还有其他方式可以构建不同于多数的法定人数。例如,我们可以为服务器的投票分配权重,并说某些服务器的投票更重要。为了获得法定人数,我们获得足够的选票,使所有选票的权重总和大于所有权重总和的一半。
另一种使用权重并在广域部署(共置)中有用的不同结构是分层结构。通过这种结构,我们将服务器分成不相交的组,并为进程分配权重。为了形成一个法定人数,我们必须从大多数组 G 中获得足够的服务器,这样对于 G 中的每个组 g,来自 g 的投票总和大于 g 中权重总和的一半。有趣的是,这种结构可以实现更小的法定人数。例如,如果我们有 9 台服务器,我们将它们分成 3 组,并为每台服务器分配 1 的权重,那么我们就能够形成大小为 4 的仲裁。请注意,两个进程子集组成了大多数大多数组中的每一个的服务器都必须有一个非空的交集。
通过 ZooKeeper,我们为用户提供了配置服务器以使用多数仲裁、权重或组层次结构的能力。
日志记录
Zookeeper 使用slf4j作为日志的抽象层。从 ZooKeeper 版本 3.8.0 开始, Logback被选为日志记录后端。为了更好的嵌入支持,计划在未来将选择最终日志实现的决定留给最终用户。因此,始终使用 slf4j api 在代码中编写日志语句,但配置 logback 以了解如何在运行时进行日志记录。请注意,slf4j 没有 FATAL 级别,以前 FATAL 级别的消息已移至 ERROR 级别。有关为 ZooKeeper 配置 logback 的信息,请参阅ZooKeeper 管理员指南的日志记录部分。
开发者指南
在代码中创建日志语句时,请遵循 slf4j 手册。在创建日志语句时,还请阅读有关性能的常见问题解答。补丁审阅者将寻找以下内容:
在正确的级别记录
slf4j 中有几个级别的日志记录。
选择合适的很重要。按照严重程度从高到低的顺序:
- ERROR 级别指定可能仍允许应用程序继续运行的错误事件。
- WARN 级别表示潜在的有害情况。
- INFO 级别指定在粗粒度级别突出显示应用程序进度的信息消息。
- 调试级别指定对调试应用程序最有用的细粒度信息事件。
- TRACE Level 指定比 DEBUG 更细粒度的信息事件。
ZooKeeper 通常在生产中运行,以便将 INFO 级别严重性和更高(更严重)的日志消息输出到日志中。
使用标准 slf4j 成语
静态消息记录
LOG.debug("process completed successfully!");
但是,当需要创建参数化消息时,请使用格式化锚。
LOG.debug("got {} messages in {} minutes",new Object[]{count,time});
命名
记录器应以使用它们的类命名。
public class Foo {
private static final Logger LOG = LoggerFactory.getLogger(Foo.class);
....
public Foo() {
LOG.info("constructing Foo");
异常处理
try {
// code
} catch (XYZException e) {
// do this
LOG.error("Something bad happened", e);
// don't do this (generally)
// LOG.error(e);
// why? because "don't do" case hides the stack trace
// continue process here as you need... recover or (re)throw
}